A look at some of the most common duplicate content problems affecting a site’s SEO and how to fix them.

Duplicate content is one of the biggest killers for a website’s rankings and one of the first things that I recommend fixing when helping a client with their SEO.
Until 2011, if a page was a duplicate, or ‘thin content’ page, the worst that would happen is that the offending page would just be filtered out the search results. Post google panda however, a high percentage of thin pages is likely to incur a site wide penalty and signal the death knell for your site’s rankings.
Here are 7 of the most common causes of duplicate content issues and the simple ways you can fix them.
Duplicate content problem 1 – WWW v Non WWW
The Problem
One of the oldest and most common causes of duplicate content and fortunately one of the easiest to fix!
Technically www.yourdomain.com is just a subdomain of domain.com and when people link to you they might decide to use either version. If you haven’t got your website configured correctly then this can cause both versions of the page to be indexed and a doubling up of your search results.
The Solutions
There are 2 ways to fix this problem and best practice is to use them both.
1) 301 Redirect one version to the other
If you are running an apache webserver with mod_rewrite installed this is simple to do using your .htaccess file.
Download the .htaccess file from your webserver and add the following 3 lines: –
RewriteEngine On
RewriteCond %{HTTP_HOST} ^yourdomain.com
RewriteRule (.*) http://www.yourdomain.com/$1 [R=301,L]What this does is tell the webserver to redirect any page at yourdomain.com to the www.yourdomain.com version.
So, for example:-
yourdomain.com/page1 would redirect to www.yourdomain.com/page1.
For a detailed explanation of how to do this, including instructions on how to set it up on a windows server, see this article on stepforth.com
2) Set Your Prefered Domain In google Webmaster Tools
Google gives you the option to set your preferred domain in your webmaster tools account. Here’s how to do it.
Firstly, you will need to set up and verify both versions of your domain (www and non www) in your webmaster tools account. Once you have verified both versions here are the steps: –
1) Click the cog icon (top right) and select ‘site settings’
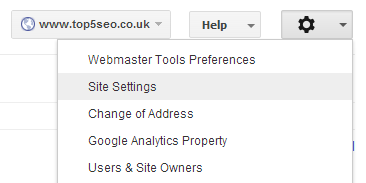
2) Set your preferred domain

Easy… and www v non www problem solved!
Duplicate Content Problem 2 – Thin Content Pages
The Problem
Thin content is basically when there is not much unique text on a web page. I discussed this problem in detail last week in my article on the importance of writing quality product descriptions as it is a problem which I often see on ecommerce sites.
The Solution
To recap on my article, you really need a minimum of 300 + words (not an exact formula) of unique content on each page of your site as anything below this is likely to be seen as too similar to other pages and trigger the duplicate content filter.
There are obviously exceptions to this (infographics, videos) and a time and a place for short posts, but make sure you don’t have too many of them. Video posts for example I would always recommend a transcription of the video, or at least a few paragraphs summarising the content.
Duplicate Content Problem 3 – Boilerplate Content
The Problem
Boilerplate content is content which is duplicated across a number of pages. Again, this is a prevalent in ecommerce sites and classic examples include things like returns policies and shipping details (often contained in tabs). The more of this boiler plate content there is on a webpage, the more unique content will be required in the article/review/product description to rank prevent duplicate content penalties.
The Solution
Move the boiler plate content to separate pages and instead of reproducing on each page, just put a link to where they can find the information. If you don’t want them to leave the page you could put this in a pop up window or lightbox.
Alternatively, cut down the volume by just listing bullet points and linking to the separate page for full details.
Duplicate Content Problem 4 – Category Sorting
The Problem
Most good quality CMS and ecommerce systems include a way to sort posts or products. For example, an ecommerce site might give you the option to sort the products by price, popularity, colour etc. This is great functionality and absolutely something you should have on your site, however, it can cause problems with duplicate content as if not correctly configured, each parameter can throw up a different page which can then be indexed, i.e.
http://www.yourdomain.com/category?orderby=colour http://www.yourdomain.com/category?orderby=price http://www.yourdomain.com/category?orderby=popularity
Before long this can mount up and you end up with hundreds (or thousands) of very similar pages in the search results.
The Solution
There is a specific meta tag which can be used to set the canonical url for a webpage, which looks like this: –
<link rel="canonical" href="http://www.yourdomain.com/category"/>
For our price, colour, popularity examples above, this tag would be placed in the <head> section of each web page and would tell google that they should not index this version of the page and that the canonical version is /category with no parameters attached.
You can read more about the rel=canonical tag and how to implement it here.
Duplicate Content Problem 5 – Junk Pages
The Problem
Wait a minute…. (I hear you cry) I don’t have junk pages on my website! Well, unfortunately you may well have. To give you an example, I have seen some shopping cart systems which have an add review link which goes to a different url for every product, i.e.
http://www.yourdomain.com/product1/addreview
http://www.yourdomain.com/product2/addreview
So, if you have 1,000 products we end up with 1,000 of these pages – all exactly the same with just an add review form. Before you know it your search results are clogged up with pages like this and you start to trigger duplicate content filters.
The Solutions
There are 2 ways to get rid of these junk pages from the index.
1) Add rel=nofollow to the links
Some SEOs may disagree with this and say that you should never add nofollow to a link on your site as you are indicating that you don’t trust a page on your own site. I believe however that this is one of the rare occasions that you should should use it as you don’t want the pages to be indexed.
2) Add A Noindex Tag
A noindex meta tag will tell google (and other search engines) not to include the page in its index. The tag should again be placed in the <head> of your document and looks like this: –
<meta name="robots" content="noindex, follow">
The ‘follow’ part tells google that although it shouldn’t index this page, it can still follow and index any links to other content that are contained within it.
You can read more about the noindex tag here.
Duplicate Content Problem 6 – Multiple Taxonomies
The Problem
This is a particular problem with blogging platforms, such as wordpress. A taxonomy is the way in which your content is sorted and, using the example of wordpress, you could choose to categorise your content by category, by tag, or by date. This can result in a lot of duplicate content.
The Solution
Another easy fix, with two simple solutions
1) Only use 1 type of taxonomy for sorting your content
If you are using wordpress, then just use categories to sort your content and don’t bother with the date archives or using tags
2) Choose 1 main taxonomy and noindex the others.
This is my preferred option as I like to give my visitors the option to browse the site a number of different ways and tags are a great way of micro sorting content. Choose your main taxonomy (normally categories) and add the meta noindex tag to your other ones.
Incidentally, if you are using wordpress, YOAST’s WordPress SEO plugin (included in my 7 have must have wordpress plugins) will sort out most of this for you. Also, check out his guide to wordpress SEO for lots more great wordpress SEO tips.
Duplicate Content Problem 7 – Content Syndication
The Problem
The final problem on my list is a major one. Syndicating your content (via RSS etc) is a great way to get your articles out there, but be careful as in some cases the syndicated version of your content can outrank or replace your original.
The Solutions
1) Make Sure Your Syndicated Content Includes A Link Back To The Source
Insisting on a link back to your site as the original source should help to ensure that your website is recognised as the definitive version of the content. Anyone who is syndicating your content should be happy to do this. If they are not and refuse to do so, then they are infringing your copyright and you should consider a DMCA request.
2) Claim Authorship
Make sure your website is set up to use google authorship with your google+ profile. This will help to ensure that when you publish you are seen as the recognised author of the content. I’ll be writing more about google authorship in the near future as it’s probably the most important thing you should be doing right now, but in the mean time you can read more about it here.
Takeaway
So, that’s 7 of the most common duplicate content problems that I come across when looking at the SEO of a website. They are all very simple to fix, so take the time to check if your site is suffering from any of them, sort them and you should see a marked improvement in your rankings. If you need help with this, or have any questions then please leave a comment below, or drop me an email.
[bigsignup]